目前最简单的方法是通过microG这个项目,然后就可以安装 Google Play Store 或者用aurora store 替代
版本更新 2025年4月
v0.3.7.250932 (只列出重点的更新):
- 修正了第三方登录Google的问题! (例如chatgpt可以用了!)
- 修复 HMS 地图相关问题 (应该解决了Google map的时候各种奇怪的问题)
- 初步支持人脸检测 API
- 其它:支持企业账号(需要手动在开启)等
如果你只是为了安装facebook,google play,google map,正常收到消息通知,不使用googlepay等服务,那么microG这个方案是非常完美!
先介绍一下 microG Project 这个项目
MicroG 项目是一个开源项目,旨在重新实现 Google 在 Android 系统中的专有应用程序和库,以支持自由软件社区的需求。简单来说,它的作用可以概括为以下几点:
- 自由软件支持:由于 Android 核心操作系统虽然是开源的,但很多核心应用和库并不是,MicroG 项目提供了一个自由软件版本的 Google 核心库和应用,使得用户可以不依赖 Google 的专有服务。
- 隐私保护:MicroG 允许用户减少或监控发送到 Google 的数据,这对于注重隐私的用户来说是一个重要的优点。
- 兼容性扩展:一些流行的开源应用程序需要 Google 的专有库才能运行,MicroG 项目通过提供这些库的自由软件版本,扩展了这些应用程序的兼容性。
- 老旧设备优化:对于老旧的 Android 设备,使用 MicroG 可以提高电池续航,因为它们不需要运行 Google 的全套服务。
- 测试和虚拟基础设施:MicroG 不仅可以在真实设备上使用,还可以在测试模拟器中替代 Google 工具,甚至用于虚拟移动基础设施
microG 提供了以下组件:
- Service Core (GmsCore):一个库应用,提供运行依赖于 Google Play 服务或 Google Maps API 的应用所需的功能。
- Services Framework Proxy (GsfProxy):一个小工具,允许使用 Google Cloud Messaging 服务的应用正常运行。
- Unified Network Location Provider (UnifiedNlp):一个库,提供基于 Wi-Fi 和蜂窝塔的地理定位服务。
- Maps API (mapsv1):一个系统库,提供与已弃用的 Google Maps API (v1) 相同的功能。
- Store (Phonesky):一个前端应用,提供访问 Google Play 商店的功能,目前还在早期开发阶段。
microG官网下载 Download - microG Project
这次用于鸿蒙系统的只需要下载:
1、microG Services
microg/GmsCore (com.google.android.gms-*-hw.apk)
也可以不安装 Play 用 aurora store 替代,但有些App会检测 Play 是否安装,这时候就需要安装 microG Companion 这个来欺骗这些 App
2、microG Companion
microg/GmsCore (com.android.vending-*-hw.apk)
注意都是下载 hw 结尾的文件,* 号代表不同版本,下载最新即可
华为的应用市场也可以搜索到,用名字直接搜索即可
3、应用商店
google play sotre 这个自行找,我是在这里下载 apkmirror
aurora store Aurora 官网下载
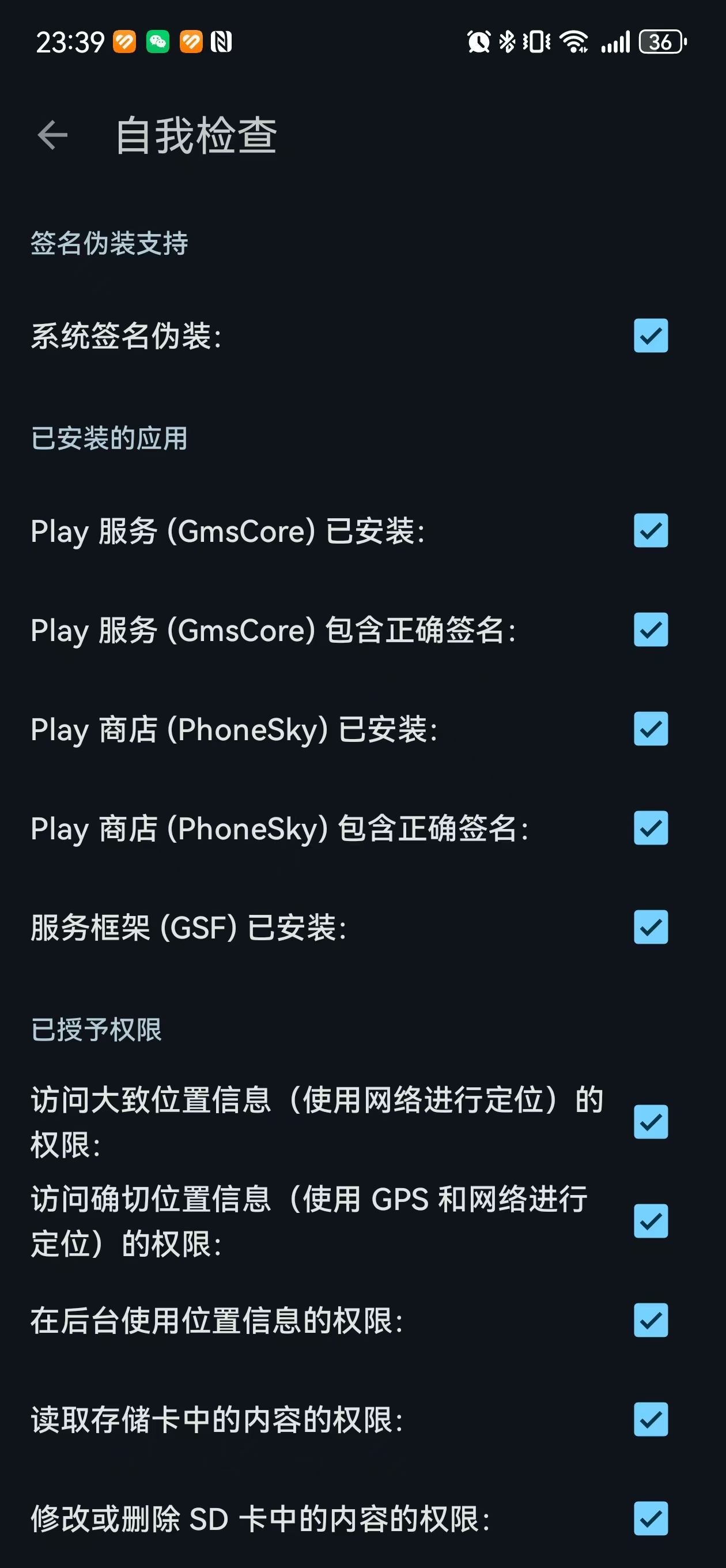
microG Services 安装后没有图标,需要在应用管理里面找到后点击右上角齿轮才可以进去
刚安装完后就会弹出设置界面,进去“自我检查” 一个个勾上,然后点击 “Google 账号” 登录自己账号